粒子滤波算法
本文最后更新于:2023年10月4日 中午
粒子滤波算法
粒子滤波(PF:Particle Filter)的思想基于蒙特卡洛方法(Monte Carlo methods),它是利用粒子集来表示概率,可以用在任何形式的状态空间模型上。其核心思想是通过从后验概率中抽取的随机状态粒子来表达其分布,是一种顺序重要性采样法(Sequential Importance Sampling)。
简单来说,粒子滤波法是指通过寻找一组在状态空间传播的随机样本对概率密度函数进行近似,以样本均值代替积分运算,从而获得状态最小方差分布的过程。这里的样本即指粒子,当样本数量
参考
从贝叶斯滤波到粒子滤波 | 朝花夕拾 (shipengx.com)
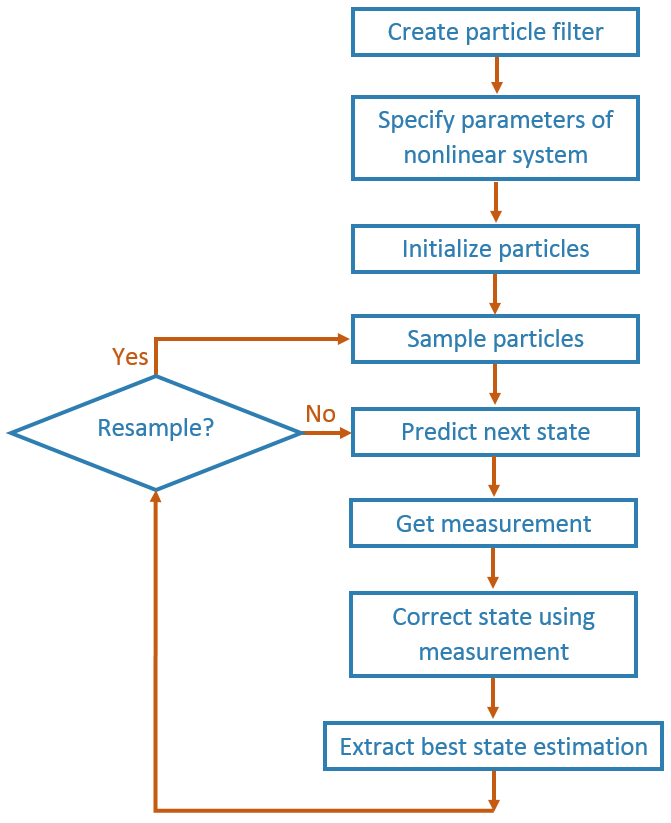
一、算法流程
(1)初始阶段
在开始滤波过程之前,需要对粒子集合进行初始化。通常可以采用在给定初值处均匀分布或其他分布形式来生成一组粒子,表示系统的初始状态。(本例中采用高斯分布初始化粒子)
(2)预测阶段
根据系统模型,对每个粒子进行状态转移预测,以得到下一时刻的粒子。
(3)更新阶段
根据系统模型得到预测值,根据测量结果获得观测数据,以观测值为均值的高斯分布进行每个粒子权重的计算,并进行归一化处理。权重表示了每个粒子与观测数据的一致程度。
(4)重采样阶段
根据粒子的权重,进行重采样操作(本例中采用独立随机采样,类似轮盘赌),增加高权重的粒子并减少低权重的粒子。重采样操作能够增加高权重粒子的数量,提高估计的准确性,可以通过设置阈值以决定是否进行重采样。
(5)滤波输出
每一次迭代都会根据系统模型和观测模型,进行状态的预测和更新,从而逐渐减小估计误差。
二、算法思想
(1)均值估计
粒子滤波利用粒子集合的均值来作为滤波器的估计值,前提是粒子集合的分布很好地“覆盖“真实值。
(2)权重计算
根据权重大小能实现”优质“粒子的大量复制,对”劣质“粒子实现淘汰制,是粒子滤波算法的核心。
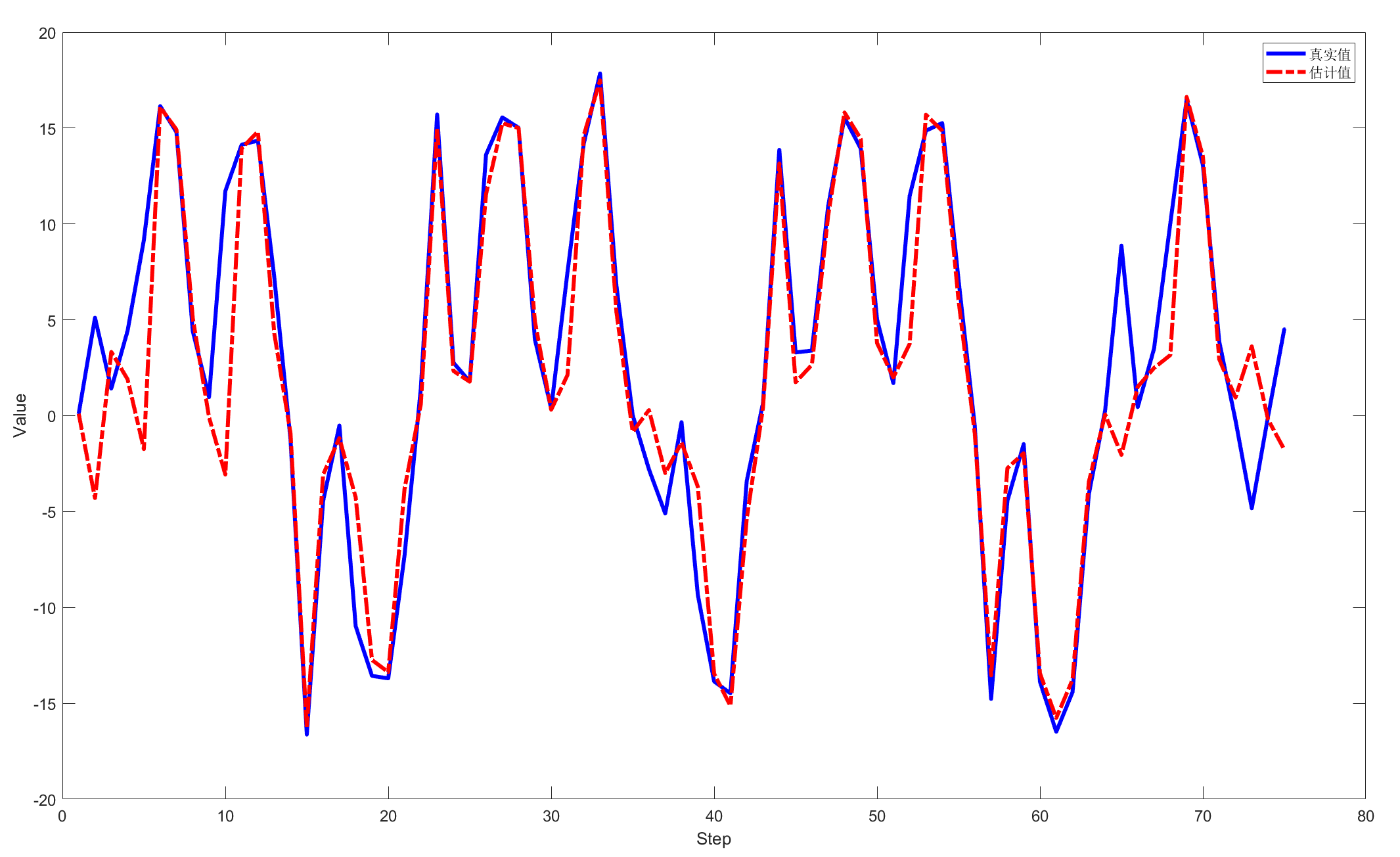
三、代码测试
软件Matlab2018a
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!
